
Unlocking the Power of Concise Information
Need to quickly grasp the core ideas from lengthy texts? This listicle covers eight key text summarization techniques, from simple frequency-based methods to sophisticated neural models like attention-based and TextRank algorithms. Learn how extractive and abstractive summarization, along with cluster-based, graph-based, and hybrid approaches, can help you efficiently condense information without sacrificing meaning. Whether you're tackling academic papers or simply staying informed, these techniques will empower you to manage information overload effectively.
1. Extractive Summarization
Extractive summarization is a foundational technique in the field of Natural Language Processing (NLP) and represents a classic approach to text summarization. It operates on the principle of identifying and extracting the most salient sentences, phrases, or passages directly from the original text without altering their wording. Think of it like a meticulous editor carefully selecting the most impactful sentences from a lengthy article to create a concise and informative summary. These extracted segments are then concatenated to form the final summary, effectively representing the core information of the source material. This method prioritizes preserving the original language and maintaining factual accuracy, making it a reliable option for summarizing factual content.

At the heart of extractive summarization lies the process of sentence scoring. Various algorithms and methods are employed to assign scores to each sentence within the original text, effectively ranking them based on their importance and relevance. These scoring methods often consider a combination of statistical and linguistic features, such as term frequency (how often a word appears), sentence position (sentences appearing earlier are often considered more important), and similarity to other sentences (sentences sharing similar themes are likely to be relevant). Common algorithms used for extractive summarization include TextRank (an adaptation of Google's PageRank algorithm applied to sentences), LexRank (which uses graph-based centrality scoring), and simpler frequency-based scoring methods. These algorithms analyze the text and identify the sentences that best encapsulate the overall meaning and central themes.
Extractive summarization excels in its ability to maintain high factual accuracy because it uses the original wording. It is also computationally efficient, allowing for fast processing of even large documents, making it suitable for real-time applications. The relative simplicity of its implementation and underlying concepts makes it a readily accessible technique for both developers and users. Moreover, it often performs well with structured documents, such as news articles and scientific papers, where the important information is often explicitly presented in a clear and organized manner.
However, extractive summarization is not without its limitations. One key drawback is the potential for limited coherence between the extracted sentences. Simply stitching together the highest-scoring sentences doesn't guarantee a smooth and naturally flowing summary. The extracted sentences may lack the necessary context or connections, leading to a disjointed reading experience. Furthermore, this method cannot generate new insights or paraphrase the original text. It relies entirely on the existing content, which can be restrictive. Finally, the quality of the generated summary is heavily dependent on the structure and clarity of the source text. A poorly organized source document is likely to yield a less coherent and informative summary.
Examples of successful implementations of extractive summarization are prevalent in many everyday applications. Google's featured snippets in search results, often providing concise answers to user queries, utilize extractive techniques. Microsoft Word's AutoSummarize feature, which allows users to quickly generate summaries of their documents, also employs this approach. News agencies like Reuters and Associated Press use extractive summarization for automated news summaries, and various academic paper abstract extraction tools facilitate quick access to the key findings of research papers.
For those interested in applying extractive summarization, several tips can enhance the quality of the generated summaries. Using multiple scoring criteria, such as combining term frequency with sentence position and similarity, can lead to a more comprehensive and accurate sentence selection process. Applying post-processing techniques, such as sentence reordering or adding connecting phrases, can improve the coherence and readability of the final summary. Considering the document's structure and formatting during the scoring process can further enhance the selection of relevant sentences. For longer documents, combining extractive summarization with clustering techniques can help group related sentences and create more organized and cohesive summaries.
Learn more about Extractive Summarization
Pioneered by Luhn (an IBM researcher in 1958) with his work on keyword extraction and sentence scoring, extractive summarization has a rich history. Google's adaptation of PageRank to TextRank further popularized the technique, as did research from Microsoft. The development of the ROUGE evaluation metric has also played a crucial role in standardizing the evaluation of summarization systems and further advancing research in this area. Extractive summarization continues to be a valuable tool in the field of NLP, providing a reliable and efficient method for condensing textual information while maintaining factual accuracy. It deserves a place in any list of text summarization techniques because it serves as a fundamental building block for many more advanced approaches and remains a practical solution for a wide variety of summarization tasks.
2. Abstractive Summarization
Abstractive summarization represents a significant leap forward in the field of text summarization techniques. Unlike extractive methods that simply string together existing sentences from the source text, abstractive summarization employs a more sophisticated approach. It delves into the meaning of the text, understanding the core concepts and relationships between ideas. This deeper understanding allows it to generate entirely new sentences that capture the essence of the original content, paraphrasing, combining ideas, and even creating novel expressions. This mirrors the way humans naturally summarize information, making the resulting summaries more concise, coherent, and engaging. It's like having a virtual assistant that reads and comprehends the text for you, then provides a succinct and insightful overview.

This advanced technique relies heavily on the power of artificial intelligence, particularly neural networks and transformer models. These models are trained on massive datasets of text and code, learning patterns and relationships within language. This allows them to not just identify keywords but to truly grasp the semantic meaning of the text. Features of abstractive summarization include generating new text, utilizing neural networks and transformer models, paraphrasing and combining multiple concepts, and producing more natural and coherent summaries. This is in stark contrast to extractive methods, which are limited to selecting and reassembling existing sentences. The ability to paraphrase and combine concepts is crucial for producing summaries that are both concise and comprehensive.
Abstractive summarization holds several advantages over extractive methods. It creates summaries that are more human-like and readable, flowing naturally from one idea to the next. This enhanced readability is particularly valuable for complex or technical texts, making them more accessible to a wider audience. Furthermore, abstractive summarization excels at capturing abstract concepts and relationships, going beyond simply identifying keywords to understand the underlying meaning. This leads to summaries that are richer in information and better capture the nuances of the original text. Finally, abstractive summarization offers greater flexibility in terms of summary length and style adaptation. You can tailor the output to your specific needs, whether you need a short, concise summary or a more detailed overview.
However, abstractive summarization is not without its drawbacks. One of the primary concerns is the risk of "hallucination," where the model generates information that is not present in the original text. This can lead to factual inaccuracies, which can be detrimental, especially in academic or professional settings. Additionally, abstractive summarization is computationally expensive and resource-intensive, requiring significant processing power and large training datasets. This can make it less accessible for individuals or organizations with limited resources. The complexity of the models also makes it more difficult to control and predict the output, which can be a challenge for applications requiring precise and consistent results.
Despite these challenges, abstractive summarization offers compelling benefits, and its adoption is rapidly growing. Examples of successful implementations include OpenAI's GPT models, Google's PEGASUS model, Facebook's BART (Bidirectional Auto-Regressive Transformers), and Quillbot's summarization tool. These tools demonstrate the power and potential of abstractive summarization for a variety of applications, from summarizing news articles and scientific papers to generating creative content.
For those interested in utilizing abstractive summarization, several tips can enhance its effectiveness. Using fine-tuned models for specific domains can improve accuracy and relevance. Implementing fact-checking mechanisms can help mitigate the risk of hallucinations and ensure the accuracy of the generated summaries. Combining abstractive methods with extractive methods in a hybrid approach can leverage the strengths of both techniques. Finally, setting appropriate length constraints can prevent the model from drifting off-topic and maintain focus on the core message.
The development and popularization of abstractive summarization can be attributed to groundbreaking research by teams at OpenAI, Google AI (PEGASUS creators), Facebook AI Research (BART), and Salesforce Research (CTRL model). Their work has paved the way for this transformative technology and continues to drive innovation in the field. This approach deserves its place on the list of text summarization techniques because it offers a higher level of sophistication and understanding than traditional methods, resulting in more concise, coherent, and insightful summaries. For a deeper dive into the application of abstractive summarization in paraphrasing, you can Learn more about Abstractive Summarization. This method proves particularly valuable for college students, high school seniors, and individuals aged 18-25 who are constantly bombarded with information and need efficient ways to synthesize and comprehend complex texts.
3. TextRank Algorithm
The TextRank algorithm stands out as a powerful and versatile technique in the realm of automatic text summarization. Inspired by Google's PageRank algorithm, which revolutionized web search by ranking web pages based on their link structure, TextRank adapts this principle to sentences within a text. Instead of web pages, TextRank treats sentences as nodes in a graph, connecting them based on their similarity. This graph-based approach allows the algorithm to identify the most important sentences by iteratively calculating their "rank" or importance score. Essentially, the algorithm operates on the premise that important sentences are likely to be connected to other important sentences, mirroring the way authoritative web pages are linked to by other authoritative pages. This unsupervised learning approach makes it particularly attractive due to its lack of reliance on training data, a significant advantage in scenarios where labeled data is scarce or unavailable.

TextRank's effectiveness lies in its ability to capture the inter-sentence relationships within a text. It constructs a graph where each sentence represents a node, and the edges between nodes represent the similarity between the corresponding sentences. This similarity can be calculated using various metrics, such as cosine similarity or Jaccard similarity, which measure the overlap in vocabulary between sentences. Once the graph is constructed, the algorithm initializes each sentence with an equal rank and then iteratively updates the ranks based on the connections in the graph. Sentences linked to by many highly ranked sentences will themselves receive a higher rank, reflecting their importance within the overall text. This iterative process continues until the ranks converge, revealing the most central and influential sentences, which are then extracted to form the summary.
One of the most significant advantages of TextRank is its unsupervised nature, meaning it doesn't require any training data. This characteristic makes it highly adaptable across various languages and domains. You don't need to train a separate model for summarizing news articles versus scientific papers, for example. Furthermore, TextRank is generally computationally efficient, particularly for medium-sized documents, making it a practical choice for many applications. Libraries like Gensim and PyTextRank provide readily available implementations of TextRank, allowing users to easily experiment with the algorithm. NLTK, a popular natural language processing library, also includes a TextRank summarizer. Numerous research papers further explore and extend the TextRank algorithm, demonstrating its influence within the NLP community.
While TextRank offers numerous advantages, it also has some limitations. It may not perform optimally with very short documents as there are fewer sentences to establish meaningful connections within the graph. The similarity calculation, although efficient for moderately sized texts, can become computationally intensive for very long documents. The choice of similarity metric also significantly impacts performance, and careful consideration is needed to select the most appropriate metric for the specific task. Furthermore, TextRank has a tendency to favor longer sentences, which can sometimes lead to summaries that include less relevant but lengthier sentences.
For students and young professionals exploring text summarization, TextRank offers a practical and accessible entry point. Its implementation in widely used libraries like Gensim and PyTextRank makes experimentation straightforward. When using TextRank, consider these tips: Experiment with different similarity metrics like cosine and Jaccard to observe their impact on the generated summary. The damping factor, a parameter that controls the influence of neighboring sentences, can also be adjusted to fine-tune the results. Careful text preprocessing, such as removing stop words and stemming, can significantly improve the accuracy of similarity calculations. For specific domains like news articles, weighting sentences based on their position (e.g., giving higher weight to sentences appearing earlier in the article) can further enhance performance.
TextRank, popularized by Rada Mihalcea and Paul Tarau in their 2004 research, represents a valuable contribution to the field of text summarization. Its elegant graph-based approach, inspired by Google's PageRank algorithm, offers a powerful and versatile method for extracting key information from text. Understanding its strengths and limitations allows users to effectively leverage TextRank for various summarization tasks and appreciate its place among essential text summarization techniques.
4. Attention-Based Neural Models
Attention-based neural models represent a significant advancement in text summarization techniques, leveraging the power of deep learning and attention mechanisms to generate concise and accurate summaries. Unlike traditional methods, these models don't just extract sentences verbatim; they understand the context and relationships between words and sentences, allowing them to paraphrase and synthesize information into abstractive summaries. This approach has led to state-of-the-art performance on various benchmarks, making it a crucial technique for anyone interested in text summarization.
These models, predominantly based on the Transformer architecture, work by assigning "attention weights" to different parts of the input text. Imagine you're reading a long article and trying to summarize it. You naturally focus on key sentences and phrases while paying less attention to less important details. Attention mechanisms mimic this human behavior. During the summarization process, the model focuses on the most relevant parts of the input text, dynamically adjusting its attention as it generates each word of the summary.
The core of these models is the encoder-decoder structure. The encoder processes the input text, transforming it into a contextualized representation. The decoder then uses this representation, guided by the attention mechanism, to generate the summary word by word. Multi-head attention, a key feature of Transformers, allows the model to capture different types of relationships between words, such as syntactic and semantic connections, further enhancing the quality of the summary. The use of pre-trained models, fine-tuned on summarization datasets, allows these models to leverage knowledge learned from massive text corpora, boosting their performance significantly.
Several successful implementations of attention-based models have emerged, pushing the boundaries of text summarization. BERT-based summarization models utilize the powerful BERT architecture for encoding the input text, leading to highly accurate and contextually rich summaries. T5 (Text-to-Text Transfer Transformer) frames summarization as a text-to-text task, enabling a unified approach to various NLP tasks. Google Research's PEGASUS model specifically targets abstractive summarization with a novel pre-training objective. Finally, LED (Longformer Encoder-Decoder) addresses the challenge of summarizing long documents by incorporating efficient attention mechanisms that can handle extended sequences.
When dealing with lengthy articles, complex topics, or the need for abstractive summaries that go beyond simple extraction, attention-based models are the preferred choice. Their ability to understand context, capture intricate relationships, and generate fluent summaries makes them ideal for these scenarios.
However, these powerful models come with their own set of challenges. They require substantial computational resources for training and inference. Their "black box" nature can make it difficult to interpret their decision-making process. There's also a potential for generating plausible but factually incorrect information, often referred to as "hallucinations." Finally, these models thrive on large datasets; training on limited data can hinder their performance.
To effectively utilize attention-based models, consider the following tips:
- Leverage pre-trained models: Start with a pre-trained model and fine-tune it on your specific domain or task. This significantly reduces training time and improves performance.
- Implement beam search: Beam search helps explore multiple possible summary outputs, leading to better quality and more fluent summaries.
- Monitor attention patterns: Visualizing attention weights can provide insights into the model's behavior and help identify potential biases or errors.
- Use gradient accumulation: For large batch training with limited GPU memory, gradient accumulation allows you to simulate larger batch sizes, improving training stability and performance.
The following infographic visualizes the core components of an attention-based neural model for text summarization: the encoder, the attention mechanism, and the decoder.
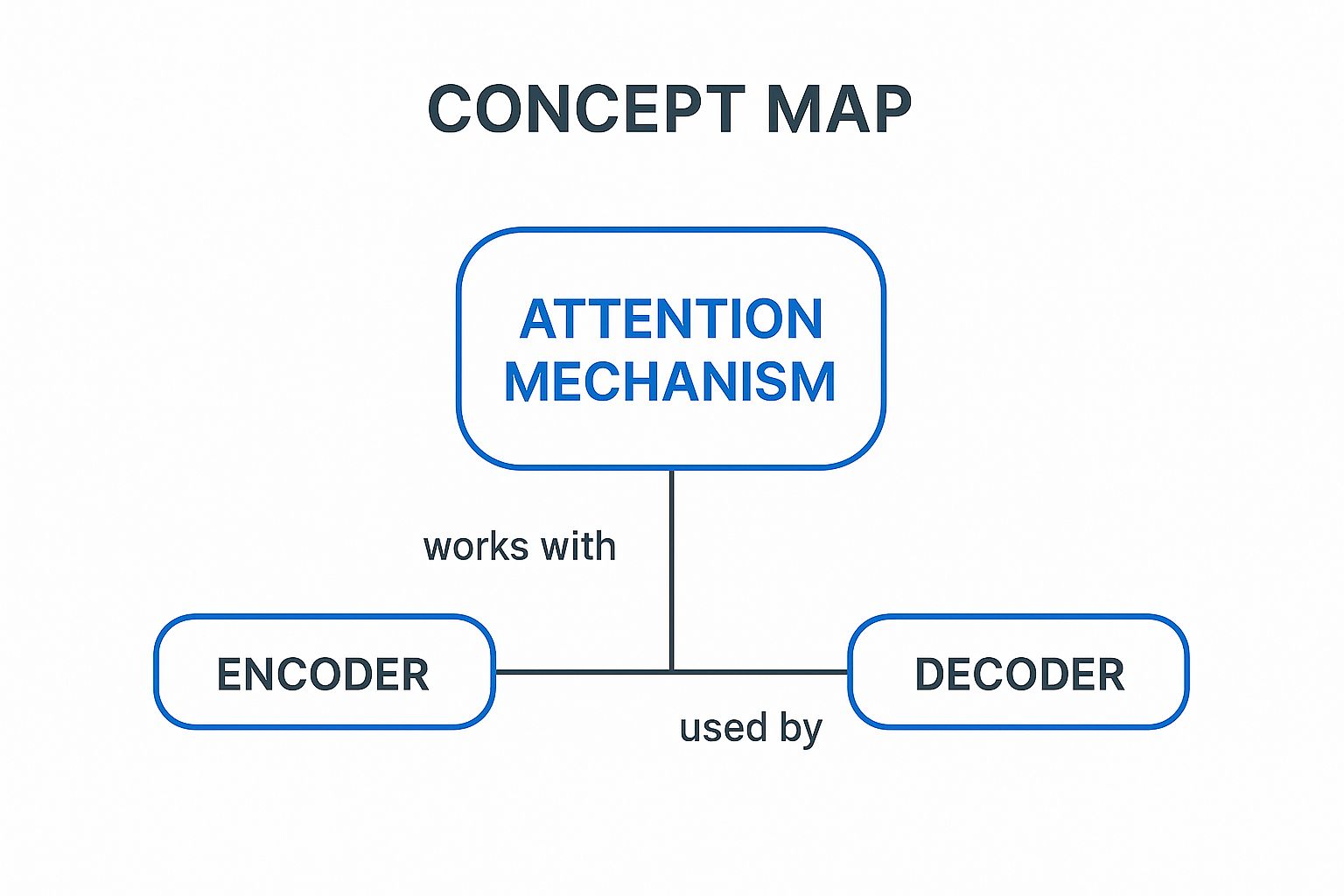
The infographic clearly demonstrates the central role of the attention mechanism, bridging the encoder's understanding of the input text with the decoder's generation of the summary. The encoder processes the input, the attention mechanism focuses on relevant parts, and the decoder generates the output based on this focused information.
The development and popularization of attention-based models are largely attributed to the groundbreaking "Attention Is All You Need" paper by Vaswani et al., along with significant contributions from Google Research (BERT, T5, PEGASUS) and OpenAI (GPT series). Hugging Face has played a crucial role in democratizing access to these powerful models, making them readily available to researchers and developers. These models are revolutionizing text summarization and represent a key area of ongoing research and development within the field of Natural Language Processing.
5. Frequency-Based Summarization
Frequency-based summarization stands as one of the foundational techniques in automatic text summarization. Its premise is simple yet powerful: words that appear frequently within a document are likely indicative of its core themes. This method leverages the frequency of terms to identify key concepts and subsequently ranks sentences based on how many of these important words they contain. The highest-scoring sentences are then extracted to form a concise summary. This makes it a particularly accessible entry point for those new to text summarization techniques. It's a great example of how a relatively simple mathematical approach can yield surprisingly effective results.
The underlying mechanism of frequency-based summarization involves several key steps. First, the text undergoes preprocessing, often including stop word removal (eliminating common words like "the," "a," and "is") and stemming (reducing words to their root form, e.g., "running" to "run"). This helps focus the analysis on meaningful content words. Next, the frequency of each remaining word is calculated. While simple word counts can be used, more sophisticated approaches like Term Frequency-Inverse Document Frequency (TF-IDF) weighting are often preferred. TF-IDF not only considers the frequency of a term within a document but also its prevalence across a larger corpus, thus downplaying common words that appear in many documents and highlighting terms specific to the document being summarized. Once word importance is determined, sentences are scored based on the cumulative importance of their constituent words. Finally, the highest-scoring sentences are selected and arranged to create the summary.
For instance, imagine summarizing a news article about a recent election. Words like "election," "candidate," "votes," and "results" are likely to appear frequently and thus receive high importance scores. Sentences containing multiple of these keywords would be ranked higher and included in the summary, effectively capturing the core information about the election outcome.
The simplicity of frequency-based summarization offers several advantages. It's easy to understand and implement, even for those without a deep background in computer science. The computational requirements are minimal, making it a fast and efficient method, particularly suitable for processing large volumes of text. Furthermore, it's relatively language-agnostic. With proper preprocessing and language-specific stop word lists, it can be applied to various languages. This makes it a versatile tool for a wide range of applications. It also tends to perform well on documents with clearly defined keywords and uneven word distribution, like scientific articles or news reports.
However, this method also has limitations. Its most significant drawback is the disregard for semantic relationships and context. It assumes that word frequency directly correlates with importance, failing to capture the nuances of language. For example, a sentence mentioning a candidate's loss might have similar keyword frequency to a sentence about their victory, leading to potentially misleading summaries. It's also prone to selecting redundant sentences, as sentences containing the same keywords might be ranked highly even if they convey similar information. Additionally, frequency-based summarization struggles with documents exhibiting uniform word distribution, such as literary texts where a wider range of vocabulary is used with less repetition. The method also fails to effectively handle synonyms or related concepts, treating "happy" and "joyful" as distinct words despite their similar meaning.
Despite its limitations, frequency-based summarization has found successful application in various domains. Early versions of Microsoft Word's AutoSummarize feature employed this technique. It's also easily implemented using libraries like NLTK, a popular Python library for natural language processing. Basic news aggregation systems and academic paper keyword extraction tools often utilize frequency-based methods for quick and efficient content processing. Learn more about Frequency-Based Summarization
To enhance the performance of frequency-based summarization, several tips can be considered. Using TF-IDF instead of raw frequency helps prioritize more relevant terms. Implementing proper stop word removal and stemming further refines the analysis. Incorporating sentence position as an additional weighting factor—giving higher scores to sentences appearing earlier in the document—can also improve summary quality. Finally, applying redundancy removal techniques in post-processing helps eliminate duplicate information and create more concise summaries.
Pioneered by figures like Hans Peter Luhn at IBM in 1958 and Gerard Salton with the SMART information retrieval system, frequency-based summarization represents a cornerstone in the field of text processing. While more advanced techniques have emerged, its simplicity and efficiency continue to make it a valuable tool for various applications, particularly for those seeking a readily understandable and implementable summarization method. For college students, high school seniors, and young adults interested in exploring text summarization, frequency-based methods offer an accessible entry point, providing valuable insights into the fundamental principles of automatic text processing.
6. Cluster-Based Summarization
Cluster-based summarization stands out among text summarization techniques for its ability to effectively condense large texts, especially those covering multiple topics. This method leverages the power of clustering algorithms to group similar sentences or paragraphs together, ensuring the final summary represents the diverse themes within the original document(s). Its sophisticated approach makes it particularly well-suited for complex texts and multi-document summarization, providing a concise yet comprehensive overview of the information. This makes it a valuable tool for anyone dealing with large volumes of text, from students researching diverse sources to professionals analyzing market trends.
At its core, cluster-based summarization operates on the principle of identifying thematic clusters within a text. The process begins by pre-processing the text, which might involve removing stop words, stemming, and converting the remaining words into numerical vectors using techniques like TF-IDF (Term Frequency-Inverse Document Frequency). These vectors represent the importance and relevance of each word within the document. Once the text is represented numerically, a clustering algorithm is applied. Popular choices include K-means, which partitions the data into k clusters based on distance from centroids, and hierarchical clustering, which builds a hierarchy of clusters based on similarity.
Once the clusters are formed, the next crucial step is selecting representative sentences from each cluster to contribute to the final summary. Several strategies exist for this selection, including choosing the sentence closest to the centroid of a cluster, selecting the sentence with the highest score based on a ranking metric (like TF-IDF), or utilizing graph-based methods that consider sentence centrality within a cluster. By drawing sentences from different clusters, the summary ensures comprehensive coverage of the diverse topics present in the original text. This diversity of coverage is what sets cluster-based summarization apart from other techniques, ensuring the summary isn't skewed towards a single dominant theme.
The advantages of this text summarization technique are numerous. It excels at handling documents discussing multiple topics by ensuring representation from each cluster, thus providing a more holistic summary. It efficiently minimizes redundancy as sentences selected for the summary are chosen from different clusters, avoiding the repetition of similar information. Furthermore, it scales well with document length and is particularly effective in multi-document summarization, making it ideal for tasks like synthesizing research findings from multiple papers or generating a concise overview of news articles on a particular event from various sources. These benefits are particularly relevant for college students, high school seniors, and young professionals (18-25 year olds) who are frequently tasked with consolidating information from multiple sources.
However, cluster-based summarization also has its limitations. Determining the optimal number of clusters (k in K-means) can be challenging. Techniques like the elbow method and silhouette analysis can assist in this process but require careful interpretation. The quality of the clustering directly impacts the quality of the summary, and choosing an inappropriate clustering algorithm or incorrect parameters can lead to poor summaries. The process of calculating sentence similarities can be computationally expensive, especially for very large datasets. Finally, there's a risk that semantically related concepts might be split into different clusters, leading to potentially fragmented summaries.
Examples of successful implementations of cluster-based summarization are readily available. Google News utilizes this technique for topic clustering and summarization, allowing users to quickly grasp the essence of news stories from diverse sources. Research databases often employ cluster-based methods for multi-document summarization, enabling researchers to efficiently synthesize findings from a large body of literature. News aggregation platforms like AllSides use similar techniques to provide balanced perspectives on news events by clustering articles from across the political spectrum. Academic literature review tools also leverage cluster-based summarization to help researchers organize and summarize large collections of academic papers.
To effectively apply cluster-based summarization, consider these tips: Use the elbow method or silhouette analysis to determine the optimal number of clusters for K-means. Experiment with different similarity metrics (cosine similarity, Jaccard index) to find the one best suited for your data. Applying dimensionality reduction techniques like Principal Component Analysis (PCA) before clustering can improve efficiency and sometimes even clustering quality. Consider hierarchical clustering if understanding the hierarchical relationship between topics is important.
Cluster-based summarization, popularized by the information retrieval research community, Google News engineers, and text mining developers, offers a powerful approach to text summarization. Its ability to condense complex, multi-topic documents into concise and representative summaries makes it an invaluable tool for navigating the ever-increasing volume of information available today. By understanding its workings, advantages, limitations, and practical tips for implementation, users can leverage this technique to effectively synthesize information and gain valuable insights from diverse text sources.
7. Graph-Based Summarization
Graph-based summarization stands out as a sophisticated technique within the landscape of text summarization methods. It leverages the power of graph theory to represent the intricate relationships within a text, moving beyond simple linear processing and opening doors to more nuanced and insightful summaries. This approach deserves its place on this list due to its ability to capture complex document structures and identify key information by analyzing connections between different text elements. This method is particularly well-suited for documents with complex interdependencies, such as scientific papers, legal documents, or multi-faceted news articles.
Instead of treating text as a simple sequence of words or sentences, graph-based summarization constructs a graphical representation of the text. In this graph, individual entities – which could be words, sentences, or even higher-level concepts – are represented as nodes. The relationships between these entities are then depicted as edges connecting the nodes. These edges can be weighted based on different factors like semantic similarity, co-occurrence frequency, or discourse relations. For instance, if two sentences share many similar words or discuss a related topic, the edge connecting their corresponding nodes would have a higher weight.
Once the graph is constructed, various graph algorithms can be applied to identify the most important nodes and edges. Centrality measures, such as betweenness centrality, closeness centrality, and eigenvector centrality, help pinpoint nodes that play crucial roles in connecting different parts of the graph. Nodes with high betweenness centrality, for example, represent key bridging concepts that connect different clusters of information. Community detection algorithms identify groups of densely connected nodes, which often correspond to different topics or subtopics within the text. Graph cuts, another powerful tool, can be used to segment the graph into smaller, coherent parts, making it easier to extract the most salient information.
The flexibility of graph representation allows for both extractive and abstractive summarization. In extractive summarization, the nodes with the highest centrality scores or those belonging to the most important communities are selected, and the corresponding sentences form the summary. In abstractive summarization, the graph structure helps in identifying key concepts and their relationships, which can then be used to generate new sentences that capture the essence of the original text.
Features of Graph-Based Summarization:
- Graph representation of text elements and relationships: Captures interdependencies beyond linear text flow.
- Centrality algorithms: Identifies important nodes based on their position and connections within the graph (betweenness, closeness, eigenvector).
- Community detection: Discovers clusters of related concepts, aiding topic identification.
- Edge weighting based on semantic similarity or co-occurrence: Represents the strength of relationships between text elements.
Pros:
- Captures complex relationships between text elements: Offers a more nuanced understanding of text structure than linear methods.
- Flexible representation: Allows for the application of various graph algorithms tailored to different summarization tasks.
- Can identify bridging concepts and key connectors: Highlights information crucial for understanding the overall context.
- Suitable for both extractive and abstractive approaches: Adaptable to different summarization paradigms.
Cons:
- Graph construction can be computationally expensive: Processing large documents can be time-consuming.
- Requires careful parameter tuning for edge weights: Performance can be sensitive to the choice of weighting scheme.
- Performance depends on the quality of relationship identification: Inaccurate relationship extraction can lead to suboptimal summaries.
- May be overkill for simple, linear documents: Simpler methods may be more efficient for straightforward texts.
Examples of Successful Implementation:
- Microsoft's concept graph for document understanding: Utilizes graph structures to represent knowledge and relationships within documents.
- Wikipedia article summarization using link graphs: Leverages the link structure between Wikipedia articles to create summaries.
- Scientific paper citation network analysis: Analyzes citation patterns to identify influential papers and research trends.
- Social media conversation thread summarization: Graphs can be used to represent the flow of conversation and identify key points.
Tips for Implementing Graph-Based Summarization:
- Choose appropriate graph algorithms for your text type: Consider the specific characteristics of your data and the desired summarization outcome.
- Experiment with different edge weight calculation methods: Explore different metrics for measuring semantic similarity or co-occurrence.
- Consider directed vs. undirected graphs based on text flow: Directed graphs can capture the flow of information, while undirected graphs focus on overall relationships.
- Use graph visualization tools to debug and understand the structure: Visualizing the graph can help identify potential issues and refine the summarization process.
Graph-based summarization, while computationally more demanding than some other techniques, offers a powerful approach to understanding and condensing complex texts. By leveraging the richness of graph representations and the versatility of graph algorithms, this technique opens up exciting possibilities for generating more insightful and informative summaries. This approach is particularly relevant for college students, high school seniors, and young adults aged 18-25 who are navigating complex academic material and information-rich online environments. This technique can be instrumental in efficiently extracting key insights from research papers, news articles, and other complex documents.
8. Hybrid Summarization Approaches
Hybrid summarization approaches represent a significant advancement in the field of text summarization techniques. They address the limitations of individual methods by intelligently combining multiple techniques to leverage their respective strengths and mitigate their weaknesses. This synergistic approach results in higher-quality summaries that are more accurate, comprehensive, and adaptable to various text types.
Instead of relying on a single method like extractive or abstractive summarization, hybrid approaches integrate multiple strategies. This often involves combining the precision of extractive methods (which identify and extract important sentences from the original text) with the fluency and conciseness of abstractive methods (which generate new sentences summarizing the main ideas). They might also incorporate other techniques like graph-based or cluster-based summarization to further enhance the coherence and relevance of the final output.
The core principle behind hybrid summarization is to create a system where the different techniques complement each other. For example, extractive methods can ensure factual accuracy by selecting sentences verbatim from the source, while abstractive methods can paraphrase and synthesize information to create a more concise and readable summary. This combination allows hybrid systems to balance accuracy with creativity, producing summaries that are both faithful to the original text and engaging for the reader.
Several architectures are employed in hybrid summarization:
- Multi-stage Pipelines: These systems process the text in multiple stages, each using a different summarization technique. For example, an initial stage might use an extractive method to identify key sentences, followed by an abstractive stage to rephrase and combine these sentences into a coherent summary.
- Ensemble Methods: These methods combine the outputs of multiple summarization techniques using voting or averaging mechanisms. This allows the system to leverage the diverse perspectives of different methods and produce a more robust and reliable summary.
- Extractive-Abstractive Hybrid Architectures: These systems tightly integrate extractive and abstractive components, often using the extractive component to guide the abstractive generation process. For instance, the extracted sentences might serve as input or constraints for the abstractive model, ensuring that the generated summary remains faithful to the original text.
- Adaptive Technique Selection: These systems dynamically select the most appropriate summarization technique based on the characteristics of the input text. For example, a system might use an extractive method for factual reports and an abstractive method for creative writing.
The benefits of hybrid summarization are numerous:
- Improved Overall Performance: Hybrid methods consistently outperform individual techniques in terms of accuracy, fluency, and conciseness.
- Robustness Across Different Document Types: They can handle a wider range of text types, from news articles to scientific papers, due to their adaptability and flexibility.
- Balance of Accuracy and Creativity: They can generate summaries that are both factually accurate and engaging to read.
- Fine-tuning for Specific Use Cases: Hybrid approaches can be tailored to specific applications, such as legal document summarization or medical report generation.
However, hybrid approaches also present some challenges:
- Increased System Complexity and Maintenance: Integrating multiple techniques requires careful design and implementation, making these systems more complex to build and maintain.
- Higher Computational Requirements: Running multiple summarization models can be computationally expensive, especially for large documents.
- Difficulty in Debugging and Optimization: Identifying and resolving errors in a complex hybrid system can be challenging.
- Potential for Conflicting Outputs: Different summarization techniques might produce conflicting outputs, requiring sophisticated mechanisms for conflict resolution.
If you're exploring the practical application of these techniques, you might find value in checking out various AI-powered text summarization tools. Several of these tools leverage hybrid approaches to offer more accurate and comprehensive summaries. They combine the strengths of extractive and abstractive methods, sometimes incorporating other techniques like graph-based or cluster-based summarization to enhance the quality and coherence of the final output.
Examples of successful hybrid summarization implementations include Google's Smart Compose, which combines multiple AI models for email and document generation, and Salesforce's hybrid CTRL+LEAD approach for sales content creation. Academic research has also explored various hybrid systems, often combining techniques like TextRank with neural network models. Enterprise AI solution providers are increasingly adopting hybrid approaches to develop customized summarization solutions for specific business needs.
When implementing hybrid summarization techniques, consider these tips:
- Start Simple: Begin with simple combinations of two techniques before moving on to complex ensembles.
- Fact Verification: Use extractive methods to verify the factual accuracy of abstractive outputs.
- Fallback Mechanisms: Implement fallback mechanisms to ensure that the system can still produce a summary even if one of the techniques fails.
- Modular Design: Design modular systems that allow for easy swapping of different components.
Hybrid summarization approaches are a powerful tool in the text summarization toolbox, offering a compelling blend of accuracy, fluency, and adaptability. By carefully combining different techniques, these systems can overcome the limitations of individual methods and produce high-quality summaries for a wide range of applications. They represent a significant step forward in the ongoing quest to automate the process of information extraction and condensation.
Comparison of 8 Summarization Techniques
| Technique | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Extractive Summarization | Low – rule/algorithm based, easy to implement | Low – computationally efficient | Accurate summaries preserving original text | News articles, reports, domain-specific documents | High factual accuracy; fast processing; simple and reliable |
| Abstractive Summarization | High – requires advanced neural models | High – needs GPUs, large training data | Human-like, coherent, and paraphrased summaries | Flexible domains needing natural language summaries | More readable and coherent; captures abstract concepts |
| TextRank Algorithm | Medium – graph-based iterative algorithm | Medium – similarity calculations intensive | Extractive ranked sentences preserving relations | Medium-length documents, multilingual summarization | No training data needed; language-independent; effective |
| Attention-Based Neural Models | High – transformer-based, complex training | Very High – large models and datasets | State-of-the-art abstractive summaries | Long documents, complex semantic understanding | Outstanding performance; handles complex semantics |
| Frequency-Based Summarization | Low – simple TF-IDF and word frequency | Low – minimal computational needs | Keyword-driven extractive summaries | Keyword-rich documents, fast and simple summarization | Simple and fast; language agnostic with preprocessing |
| Cluster-Based Summarization | Medium to High – clustering + sentence selection | Medium to High – similarity and clustering costs | Diverse topic coverage with reduced redundancy | Multi-topic documents, multi-document summarization | Ensures topic diversity; reduces redundancy |
| Graph-Based Summarization | High – graph construction + complex algorithms | High – computationally expensive | Summaries capturing complex relationships | Complex documents with rich relational structures | Captures nuanced relationships; flexible algorithm use |
| Hybrid Summarization Approaches | Very High – combines multiple techniques | Very High – combines resource needs | Balanced, high-quality summaries | Varied document types requiring accuracy and creativity | Best overall performance; robustness; adaptable |
Choosing the Right Summarization Tool for Your Needs
This article explored a range of text summarization techniques, from fundamental approaches like extractive and abstractive summarization to more advanced algorithms like TextRank, attention-based models, and graph-based methods. We also touched on the benefits of frequency-based, cluster-based, and hybrid summarization approaches. Understanding the core differences between these text summarization techniques empowers you to efficiently process information, extract key insights from lengthy texts, and ultimately, enhance your learning and research capabilities. Mastering these concepts is crucial for navigating the ever-increasing volume of information available today, allowing you to quickly distill complex topics into manageable summaries. This ability is invaluable, not just for academic success, but also for professional development and lifelong learning.
The right text summarization technique depends on the specific task, content type, and available resources. By understanding the strengths and weaknesses of each method – from simple frequency-based approaches to sophisticated AI-powered models – you can choose the most appropriate approach to effectively condense information while preserving key insights. From condensing research papers to quickly grasping the main points of news articles, the ability to summarize text efficiently will significantly boost your productivity and comprehension.
Ready to put these text summarization techniques into practice and supercharge your academic workflow? Explore the AI-powered tools at SmartStudi – including our Large Text Summarizer, AI & Plagiarism Detectors, and Text Paraphraser/Humanizer – designed to help you effectively summarize, analyze, and refine your writing. SmartStudi provides the practical application of many of the techniques discussed, allowing you to experience the benefits of automated summarization firsthand.